Ang pagho-host at pamamahala ng data sa mga database at data warehouse ay palaging isang abalang at mahirap na gawain. Nangangailangan ito ng maraming resource at computational power para magkaroon ng kahulugan ang data. Ang Amazon Web Services ay may one-stop na solusyon para sa layuning ito. Mayroon itong serbisyong tinatawag na Amazon Redshift na ganap na namamahala sa mga warehouse ng data ng mga user.
Ipapaliwanag ng artikulong ito nang detalyado ang Amazon Redshift kasama ang arkitektura ng data warehouse nito. Ang lahat ng mga bahagi ng arkitektura ng sistema ng data warehouse ng Redshift ay ipapaliwanag nang detalyado.
Ano ang Amazon Redshift?
Ang IT ay isang serbisyo ng data warehousing na ibinigay ng Amazon. Mahusay nitong pinamamahalaan at sinusuri ang malalaking dataset para sa analytics at pag-uulat. Ito ay binuo sa isang columnar storage model. Gumagamit ito ng mga kumpol ng mga compute node na kinokontrol ng isang leader node upang magbigay ng mataas na pagganap ng pagproseso ng data.
Kinukuha nito ang data mula sa iba't ibang mga mapagkukunan at pinagsama ito upang makagawa ng isang warehouse ng data. Nag-aalok ito ng iba't ibang mga tampok, tulad ng pagbabahagi ng data at real-time na analytics. Tingnan ang larawan sa ibaba para sa pag-unawa sa mga tampok at kakayahan ng Amazon Redshift:
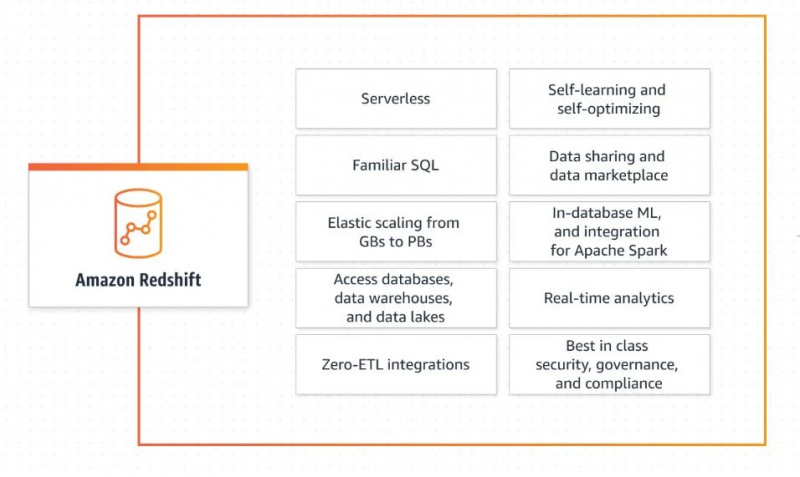
Pumunta tayo sa arkitektura ng system ng data warehouse nito ngayon.
Ano ang Amazon Redshift Data Warehouse System Architecture?
Ang arkitektura ng system na ito ay may tatlong pangunahing bahagi. Ang mga bahaging ito ay:
- Imbakan
- Pagpapabilis
- Pagtutuos
Intindihin natin ang kanilang mga layunin:
Imbakan
Ang bahagi ng imbakan ay tumatalakay sa mga serbisyo ng imbakan na mayroon ang Redshift. Mayroon itong sariling pinamamahalaang opsyon sa serbisyo ng imbakan pati na rin ang opsyon na S3 bucket.
Pagpapabilis
Ang acceleration part ay nakadepende sa storage service na ginagamit at sa computational power na ginagamit. Ang imbakan na pinamamahalaan ng Redshift ay mas mabilis kumpara sa iba pang mga opsyon sa storage
Pagtutuos
Ang bahagi ng pag-compute ay lubos na tumatalakay sa kapangyarihan ng pag-compute na ginagamit. Ginagawa ang pagkalkula gamit ang mga kumpol at ang mga kumpol ay may mga node. Ang mga node naman ay may mga hiwa.
Upang mas maunawaan ang lahat ng elemento at bahagi ng arkitektura na ito, tingnan ang larawan sa ibaba:
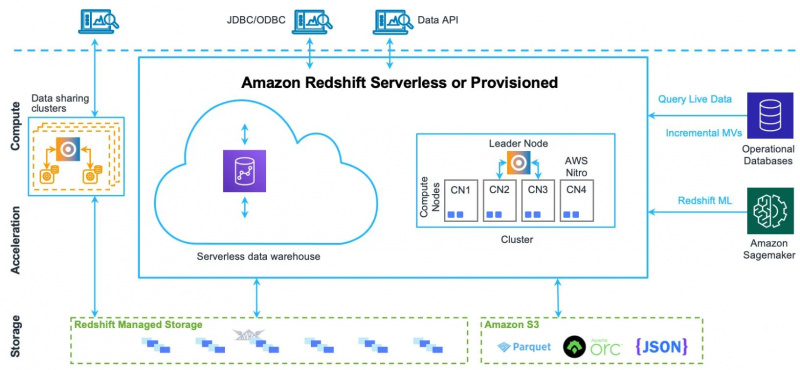
Unawain natin ang mga bahagi nito nang paisa-isa.
Ano ang mga Arkitektural na Bahagi ng Amazon Redshift?
Ang mga sumusunod ay ang mga bahagi ng arkitektura ng Amazon Redshift:
- Mga kumpol
- Mga node
- Mga Hiwa ng Node
- Imbakan
- Panloob na Network
- Mga database
Isa-isa nating talakayin ang mga ito:
Mga kumpol
Ang cluster ay ang pangunahing at pangunahing yunit. Binubuo ito ng isang bilang ng mga node. Kung ang isang cluster ay binubuo ng maramihang mga compute node, ang isang karagdagang node ng pinuno ay papasok upang i-coordinate ang mga aktibidad ng mga compute node na ito at pamahalaan ang panlabas na komunikasyon.
Mga node
Ang mga node sa mga cluster ay may dalawang uri. Ito ay:
- Pinuno Node
- Compute Node
Unawain natin ang mga ito nang isa-isa:
Pinuno Node
Pinamamahalaan nito ang komunikasyon sa mga programa ng kliyente at nagko-coordinate ng mga pakikipag-ugnayan sa mga compute node. Ang node ng pinuno ay gumaganap ng isang mahalagang papel sa pagsasagawa ng mga kumplikadong query. Nag-compile ito ng code batay sa execution plan na ibinabahagi sa pag-compute ng mga node at nagtatalaga ng mga bahagi ng data sa bawat indibidwal na compute node.
Compute Node
Ang mga compute node ay ang backbone ng arkitektura ng Amazon Redshift. Nagsasagawa sila ng parehong pag-iimbak at pagproseso ng data. Ang mga ito ay may nakalaang mapagkukunan, tulad ng memorya at CPU.
Mga Hiwa ng Node
Ang mga compute node ay nahahati pa sa mga hiwa. Nagtutulungan ang mga slice na ito upang iproseso ang mga nakatalagang workload at makamit ang parallelism upang mapahusay ang pagproseso ng query.
Imbakan
Ang imbakan ng data sa loob ng Amazon Redshift ay pinamamahalaan ng 'Redshift Managed Storage (RMS)'. Ito ay may kakayahang mag-scale ng storage nang nakapag-iisa gamit ang 'Amazon S3' storage. Gumagamit ang RMS ng high-performance na SSD-based na lokal na storage bilang tier-1 cache na nag-o-optimize ng performance.
Panloob na Network
Ang panloob na network na ito sa Amazon Redshift ay tumutulong sa mabilis at secure na komunikasyon sa pagitan ng mga leader node at compute node. Ang network na ito ay hindi direktang naa-access sa mga application ng kliyente.
Mga database
Ang mga cluster ay may isa o higit pang mga database. Ang data mula sa mga database na ito ay nasa mga compute node. Ang mga aplikasyon ng kliyente ay nakikipag-ugnayan sa node ng pinuno. Pinamamahalaan ng compute node ang pagpapatupad ng query sa mga compute node.
Ito ay tungkol sa Amazon Redshift at mga elemento ng arkitektura nito. Ang artikulong ito ay komprehensibong ipinaliwanag ang gumaganang mga bahagi ng Amazon Redshift
Konklusyon
Ang arkitektura ng Amazon Redshift ay ang dahilan kung saan nakatayo ang mga kakayahan nito. Ang leader node ay kumokontrol at namamahala sa mga compute node at node slices ay tumutulong sa parallel processing. Gumagamit ang Redshift Managed Storage ng SSD-based na storage para mapahusay ang performance. Ipinaliwanag ng artikulong ito ang Amazon Redshift Data Warehouse System Architecture.