Ipapaliwanag ng gabay na ito ang mga crawler ng listahan sa AWS.
Ano ang Mga List-Crawler sa AWS?
Ang Crawler ay isang bahagi ng AWS Glue na ginagamit upang i-crawl ang lokasyon ng data at ibinabalik ang impormasyong iyon sa catalog. Ang impormasyong kinokolekta ng isang crawler ay maaaring mga uri ng data ng data, istraktura ng schema, o sa madaling salita, nangongolekta ito ng metadata. Magagamit din ang crawler kasama ang Data catalog na ginagamit kapag inilipat ang data sa loob ng Glue ecosystem habang gumagamit ng mga trabaho sa ETL, atbp.
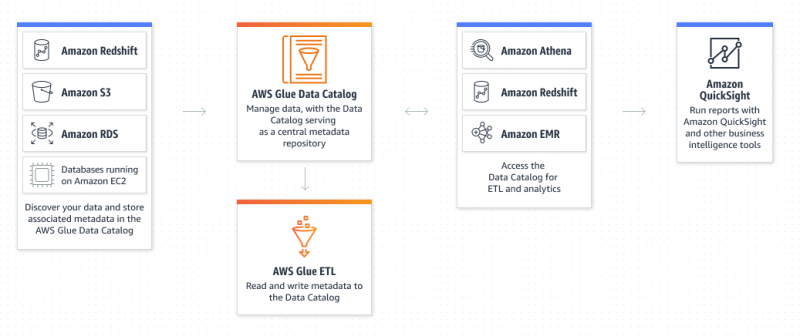
Ano ang Amazon Glue Service?
Ang AWS Glue ay isang serbisyo ng Amazon Extract Transform and Load na nagbibigay-daan sa user na ayusin, hanapin, ilipat, at baguhin ang lahat ng data. Ang AWS Glue ay walang server dahil hindi kailangan ng user na i-provision at i-configure ang mga server o pamahalaan ang mga life cycle. Ang catalog ng data at mga crawler ay ang mga bahagi ng AWS Glue na gumaganap bilang patuloy na imbakan ng metadata:

Paano Gumawa ng Crawler sa AWS?
Upang gumawa ng crawler sa AWS, bisitahin ang serbisyo ng AWS Glue mula sa AWS Management Console:
Tumungo sa ' Mga crawler ” na pahina sa pamamagitan ng pag-click sa pangalan nito mula sa kaliwang panel:
Mag-click sa “ Lumikha ng crawler 'button:
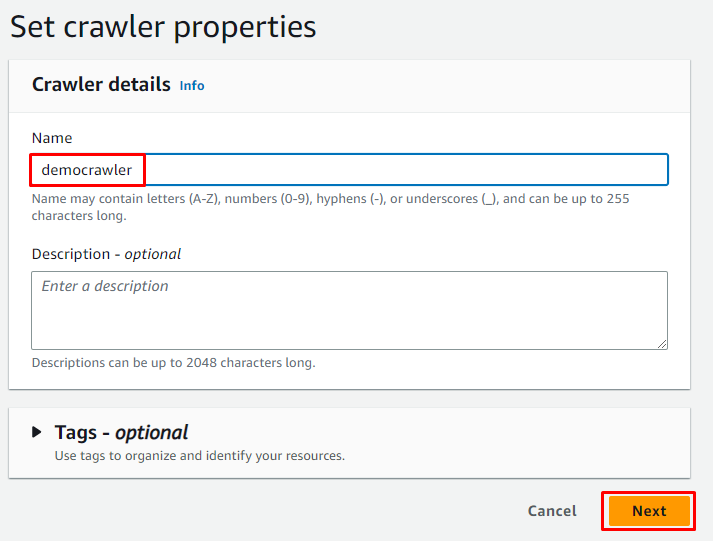
I-type ang pangalan ng crawler at mag-click sa “ Susunod 'button:
Piliin ang pagpipilian sa pagmamapa para sa mga talahanayan ng pandikit at mag-click sa ' Magdagdag ng pinagmulan ” button upang makakuha ng data mula sa:

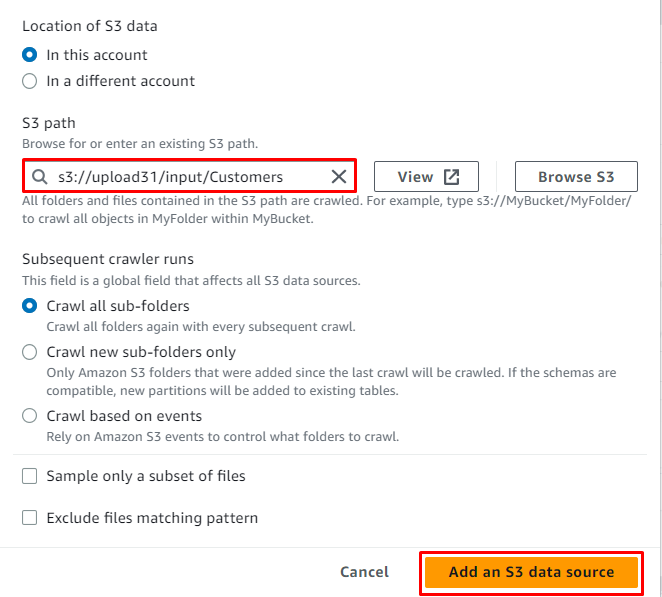
Piliin ang serbisyo ng S3 at i-click ang “ I-browse ang S3 ” button upang makuha ang lokasyon ng pinagmulan:

Piliin lamang ang S3 folder at i-click ang ' Pumili 'button:

Kapag naidagdag na ang lokasyon sa pinagmulan, i-click lang ang “ Magdagdag ng S3 data source 'button:
Mag-click sa “ Susunod 'button:

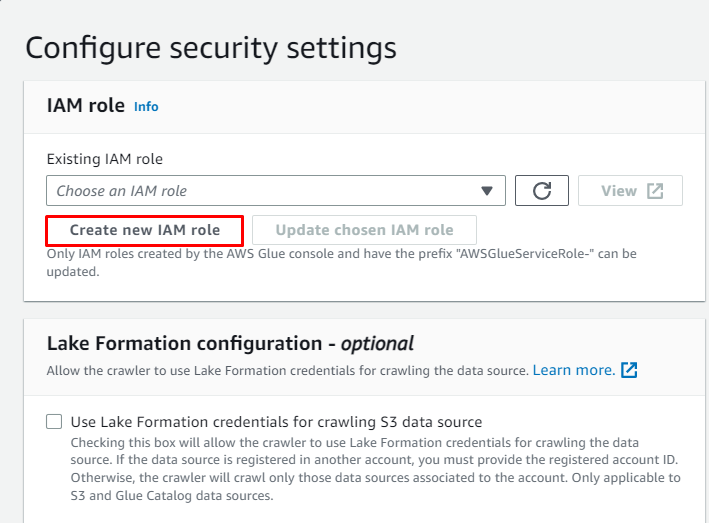
Mag-click sa “ Gumawa ng bagong tungkulin ng IAM 'button mula sa' I-configure ang mga setting ng seguridad ” seksyon:
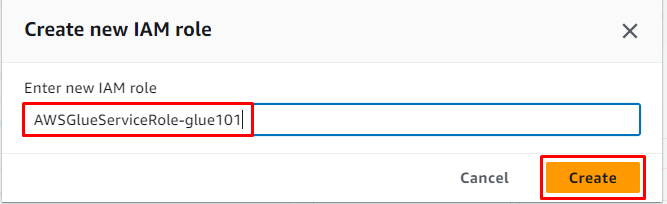
Ilagay ang pangalan ng tungkulin at mag-click sa “ Lumikha 'button:
Pagkatapos nito, i-click lamang ang ' Susunod 'button:

Piliin ang target na database at i-type ang pangalan na gagamitin para sa talahanayan:
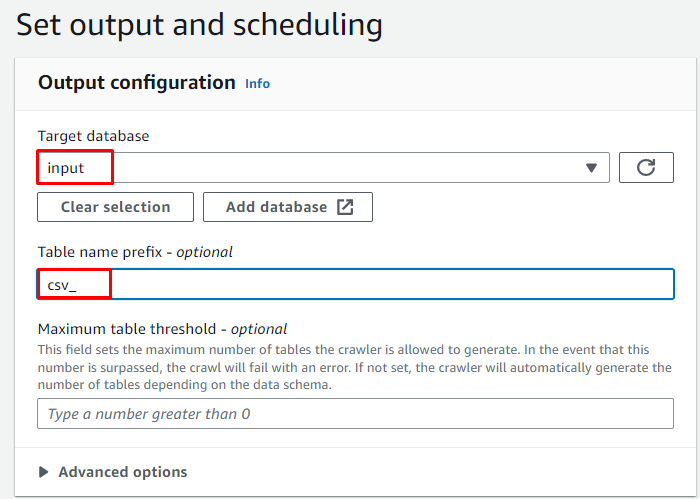
Iskedyul ang crawler para sa ' On demand ” at i-click ang “ Susunod 'button:
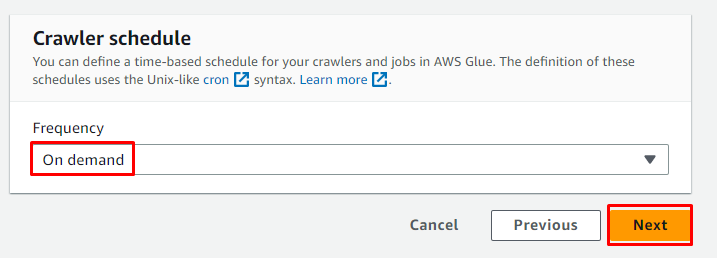
Suriin ang pagsasaayos at mag-click sa “ Lumikha ng crawler 'button:
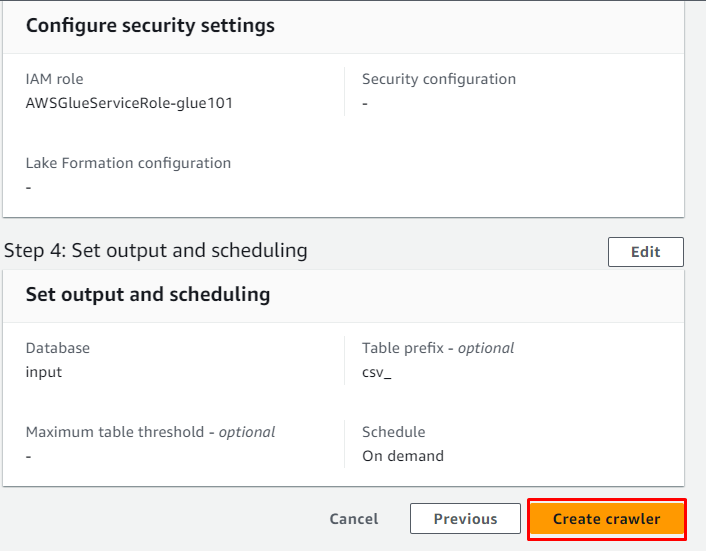
Matagumpay na nalikha ang crawler at maaari itong magamit upang kunin ang data mula sa pinagmulan sa pamamagitan ng pag-click sa ' Takbo 'button:

Iyon lang ang tungkol sa mga crawler ng listahan sa AWS.
Konklusyon
Ang ListCrawler ay bahagi ng serbisyo ng AWS Glue na maaaring magamit upang i-crawl ang impormasyon mula sa mga mapagkukunan at bumalik sa catalog. Maaaring gamitin ang mga katalogo ng data at crawler upang mangolekta ng data upang makakuha ng impormasyon tungkol sa data na kilala bilang metadata. Ang user ay maaari ding lumikha ng isang crawler mula sa AWS Glue upang makakuha ng data mula sa serbisyo ng S3 o iba pang mga mapagkukunan at maglagay ng mga talahanayan ng paglikha sa database. Ipinaliwanag ng gabay na ito ang ListCrawlers sa AWS at kung paano gawin ang mga ito.