Mabilis na Balangkas
Ang post na ito ay naglalaman ng mga sumusunod na seksyon:
- Paano Gumamit ng Async API Agent sa LangChain
- Paraan 1: Paggamit ng Serial na Pagpapatupad
- Paraan 2: Paggamit ng Kasabay na Pagpapatupad
- Konklusyon
Paano Gumamit ng Async API Agent sa LangChain?
Ang mga modelo ng chat ay nagsasagawa ng maraming gawain nang sabay-sabay tulad ng pag-unawa sa istruktura ng prompt, mga kumplikado nito, pagkuha ng impormasyon, at marami pa. Ang paggamit ng ahente ng Async API sa LangChain ay nagbibigay-daan sa user na bumuo ng mahusay na mga modelo ng chat na makakasagot ng maraming tanong sa isang pagkakataon. Upang matutunan ang proseso ng paggamit ng ahente ng Async API sa LangChain, sundin lamang ang gabay na ito:
Hakbang 1: Pag-install ng Mga Framework
Una sa lahat, i-install ang LangChain framework para makuha ang mga dependency nito mula sa Python package manager:
pip install langchain
Pagkatapos nito, i-install ang OpenAI module upang bumuo ng modelo ng wika tulad ng llm at itakda ang kapaligiran nito:
pip install openai
Hakbang 2: OpenAI Environment
Ang susunod na hakbang pagkatapos ng pag-install ng mga module ay pagtatatag ng kapaligiran gamit ang API key ng OpenAI at Serper API para maghanap ng data mula sa Google:
angkat ikaw
angkat getpass
ikaw . humigit-kumulang [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'OpenAI API Key:' )
ikaw . humigit-kumulang [ 'SERPER_API_KEY' ] = getpass . getpass ( 'Serper API Key:' )
Hakbang 3: Pag-import ng Mga Aklatan
Ngayong nakatakda na ang kapaligiran, i-import lamang ang mga kinakailangang aklatan tulad ng asyncio at iba pang mga aklatan gamit ang mga dependency ng LangChain:
mula sa langchain. mga ahente angkat initialize_agent , load_toolsangkat oras
angkat asyncio
mula sa langchain. mga ahente angkat Uri ng Ahente
mula sa langchain. llms angkat OpenAI
mula sa langchain. mga callback . stdout angkat StdOutCallbackHandler
mula sa langchain. mga callback . mga tracer angkat LangChainTracer
mula sa aiohttp angkat ClientSession
Hakbang 4: Mga Tanong sa Pag-setup
Magtakda ng dataset ng tanong na naglalaman ng maraming query na nauugnay sa iba't ibang domain o paksa na maaaring hanapin sa internet (Google):
mga tanong = ['Sino ang nagwagi ng U.S. Open championship sa 2021' ,
'Ano ang edad ng kasintahan ni Olivia Wilde' ,
'Sino ang nanalo ng formula 1 world title' ,
'Sino ang nanalo sa US Open women's final noong 2021' ,
'Sino ang asawa ni Beyonce at Ano ang kanyang edad' ,
]
Paraan 1: Paggamit ng Serial na Pagpapatupad
Kapag nakumpleto na ang lahat ng hakbang, isagawa lang ang mga tanong para makuha ang lahat ng sagot gamit ang serial execution. Nangangahulugan ito na ang isang tanong ay isasagawa/ipapakita sa isang pagkakataon at ibabalik din ang kumpletong oras na kinakailangan upang maisagawa ang mga tanong na ito:
llm = OpenAI ( temperatura = 0 )mga kasangkapan = load_tools ( [ 'google-header' , 'llm-math' ] , llm = llm )
ahente = initialize_agent (
mga kasangkapan , llm , ahente = Uri ng Ahente. ZERO_SHOT_REACT_DESCRIPTION , verbose = totoo
)
s = oras . perf_counter ( )
#configuring time counter upang makuha ang oras na ginamit para sa kumpletong proseso
para sa q sa mga tanong:
ahente. tumakbo ( q )
lumipas na = oras . perf_counter ( ) - s
#print ang kabuuang oras na ginamit ng ahente para makuha ang mga sagot
print ( f 'Isinagawa ang serial sa loob ng {elapsed:0.2f} na segundo.' )
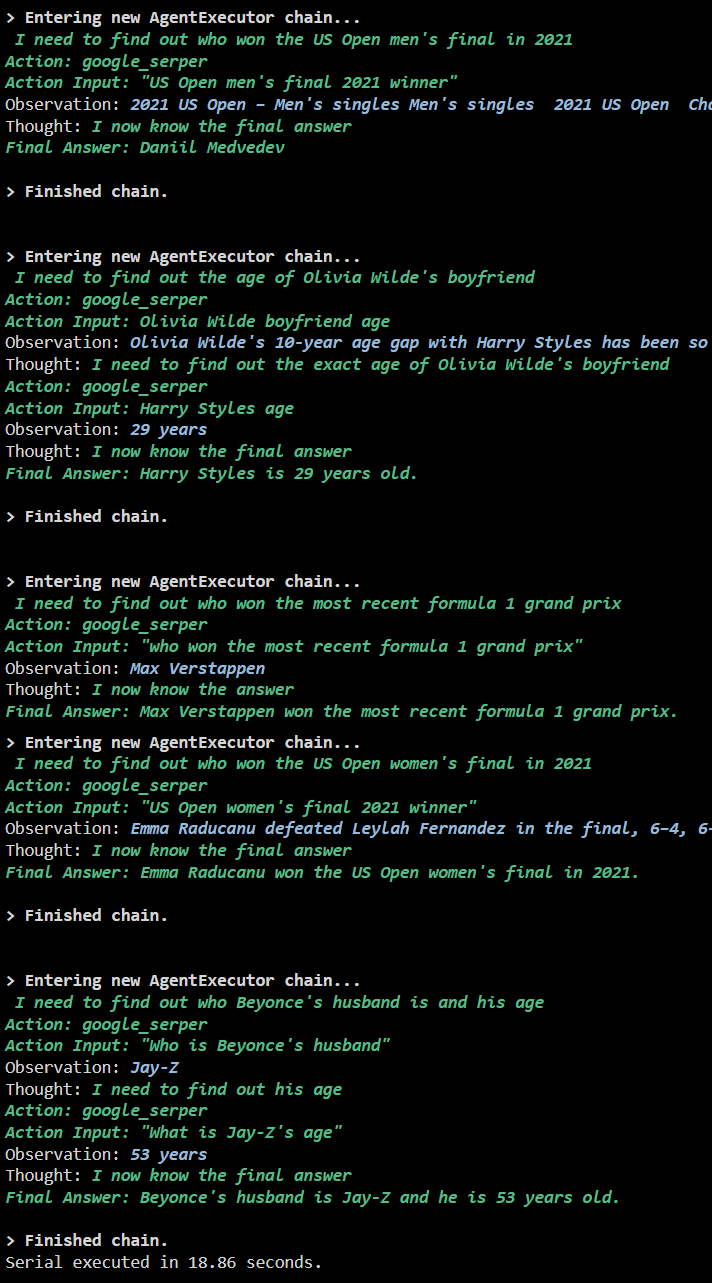
Output
Ipinapakita ng sumusunod na screenshot na ang bawat tanong ay sinasagot sa isang hiwalay na chain at kapag natapos na ang unang chain, magiging aktibo ang pangalawang chain. Ang serial execution ay tumatagal ng mas maraming oras upang makuha ang lahat ng mga sagot nang paisa-isa:
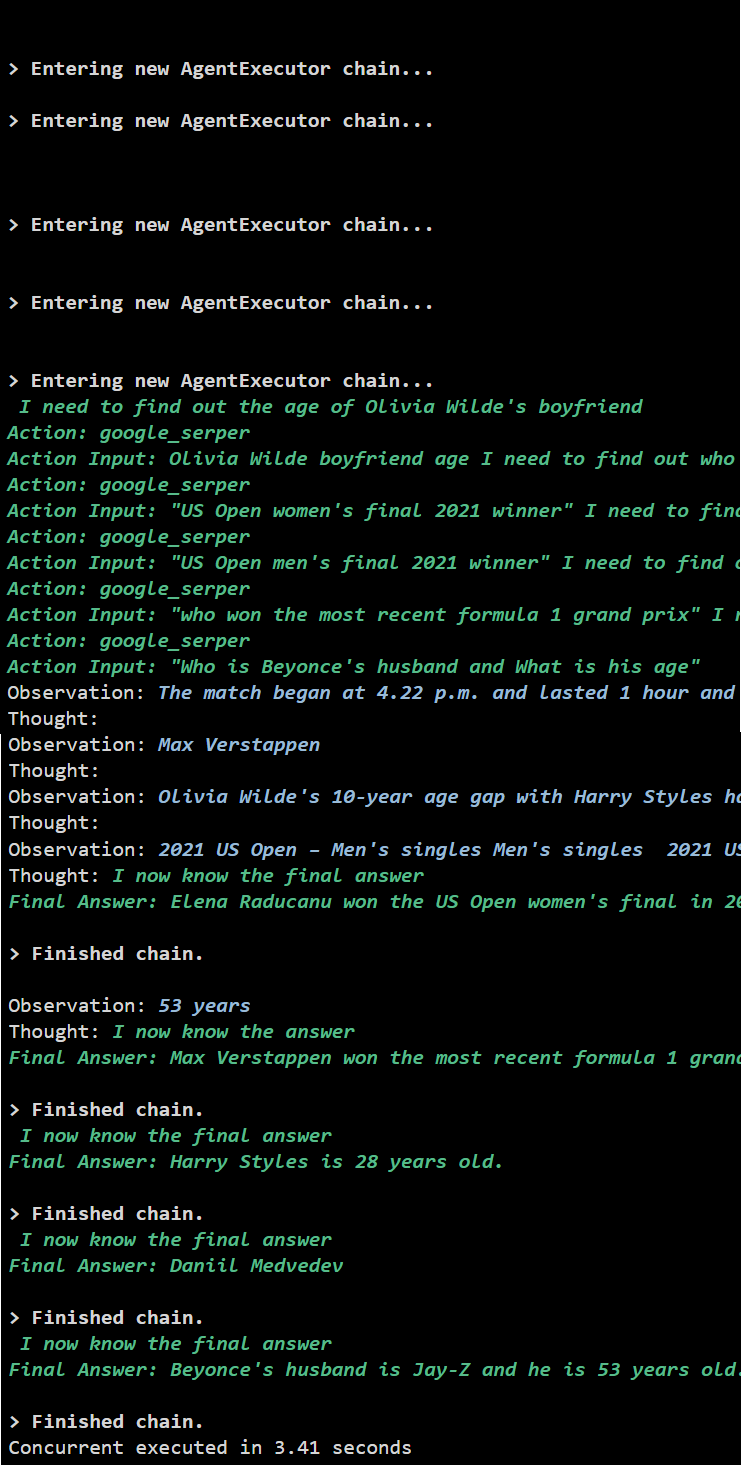
Paraan 2: Paggamit ng Kasabay na Pagpapatupad
Kinukuha ng Concurrent execution method ang lahat ng tanong at sabay-sabay na nakukuha ang kanilang mga sagot.
llm = OpenAI ( temperatura = 0 )mga kasangkapan = load_tools ( [ 'google-header' , 'llm-math' ] , llm = llm )
#Configuring agent gamit ang mga tool sa itaas upang makakuha ng mga sagot nang sabay-sabay
ahente = initialize_agent (
mga kasangkapan , llm , ahente = Uri ng Ahente. ZERO_SHOT_REACT_DESCRIPTION , verbose = totoo
)
#configuring time counter para makuha ang oras na ginamit para sa kumpletong proseso
s = oras . perf_counter ( )
mga gawain = [ ahente. sakit ( q ) para sa q sa mga tanong ]
maghintay ng asyncio. magtipon ( *mga gawain )
lumipas na = oras . perf_counter ( ) - s
#print ang kabuuang oras na ginamit ng ahente para makuha ang mga sagot
print ( f 'Kasabay na isinagawa sa loob ng {elapsed:0.2f} na segundo' )
Output
Kinukuha ng sabay-sabay na pagpapatupad ang lahat ng data sa parehong oras at tumatagal ng mas kaunting oras kaysa sa serial execution:
Iyon lang ang tungkol sa paggamit ng ahente ng Async API sa LangChain.
Konklusyon
Para magamit ang ahente ng Async API sa LangChain, i-install lang ang mga module para i-import ang mga library mula sa mga dependency nito para makuha ang asyncio library. Pagkatapos nito, i-set up ang mga environment gamit ang OpenAI at Serper API key sa pamamagitan ng pag-sign in sa kani-kanilang account. I-configure ang hanay ng mga tanong na nauugnay sa iba't ibang paksa at isagawa ang mga chain nang sunud-sunod at sabay-sabay upang makuha ang kanilang oras ng pagpapatupad. Ang gabay na ito ay nagpapaliwanag sa proseso ng paggamit ng ahente ng Async API sa LangChain.