Sa artikulong ito, tatalakayin natin kung paano maglaan IBA memorya sa pamamagitan ng ' pytorch_cuda_alloc_conf ” paraan.
Ano ang 'pytorch_cuda_alloc_conf' na Paraan sa PyTorch?
Sa panimula, ang ' pytorch_cuda_alloc_conf ” ay isang variable ng kapaligiran sa loob ng balangkas ng PyTorch. Ang variable na ito ay nagbibigay-daan sa mahusay na pamamahala ng mga magagamit na mapagkukunan sa pagpoproseso na nangangahulugan na ang mga modelo ay tumatakbo at gumagawa ng mga resulta sa pinakamaliit na posibleng tagal ng oras. Kung hindi ginawa ng maayos, ang ' IBA Ang 'computation platform ay magpapakita ng ' wala sa memorya ” error at makakaapekto sa runtime. Mga modelo na dapat sanayin sa malalaking volume ng data o may malaking ' mga laki ng batch ” ay maaaring makagawa ng mga error sa runtime dahil maaaring hindi sapat ang mga default na setting para sa kanila.
Ang ' pytorch_cuda_alloc_conf 'Ang variable ay gumagamit ng sumusunod na ' mga pagpipilian ” para pangasiwaan ang paglalaan ng mapagkukunan:
- katutubo : Ginagamit ng opsyong ito ang mga available nang setting sa PyTorch para maglaan ng memory sa kasalukuyang modelo.
- max_split_size_mb : Tinitiyak nito na ang anumang bloke ng code na mas malaki kaysa sa tinukoy na laki ay hindi nahahati. Ito ay isang makapangyarihang kasangkapan upang maiwasan ang ' pagkakapira-piraso ”. Gagamitin namin ang opsyong ito para sa pagpapakita sa artikulong ito.
- roundup_power2_divisions : Ang opsyong ito ay nag-round up sa laki ng alokasyon sa pinakamalapit na “ kapangyarihan ng 2 ” dibisyon sa megabytes (MB).
- roundup_bypass_threshold_mb: Maaari nitong bilugan ang laki ng alokasyon para sa anumang listahan ng kahilingan nang higit sa tinukoy na threshold.
- garbage_collection_threshold : Pinipigilan nito ang latency sa pamamagitan ng paggamit ng magagamit na memorya mula sa GPU sa real time upang matiyak na ang reclaim-all protocol ay hindi sinimulan.
Paano Maglaan ng Memorya Gamit ang Paraang 'pytorch_cuda_alloc_conf'?
Ang anumang modelo na may malaking dataset ay nangangailangan ng karagdagang paglalaan ng memorya na mas malaki kaysa sa itinakda bilang default. Kailangang tukuyin ang custom na alokasyon na isinasaalang-alang ang mga kinakailangan ng modelo at magagamit na mapagkukunan ng hardware.
Sundin ang mga hakbang na ibinigay sa ibaba upang gamitin ang ' pytorch_cuda_alloc_conf ” na paraan sa Google Colab IDE upang maglaan ng higit pang memorya sa isang kumplikadong modelo ng machine-learning:
Hakbang 1: Buksan ang Google Colab
Maghanap sa Google Nagtutulungan sa browser at lumikha ng ' Bagong Notebook 'upang magsimulang magtrabaho:
Hakbang 2: Mag-set up ng Custom na PyTorch Model
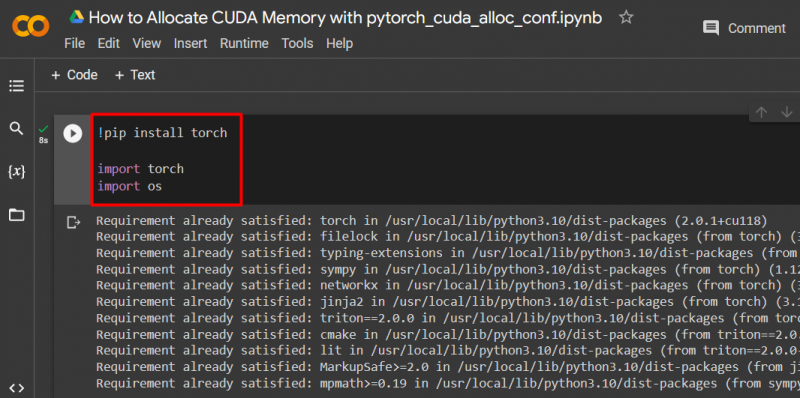
Mag-set up ng modelo ng PyTorch sa pamamagitan ng paggamit ng “ !pip ” package sa pag-install para i-install ang “ tanglaw 'aklatan at ang' angkat 'utos na mag-import' tanglaw 'at' ikaw ” mga aklatan sa proyekto:
import na tanglaw
import sa amin
Ang mga sumusunod na aklatan ay kailangan para sa proyektong ito:
- Tanglaw – Ito ang pangunahing aklatan kung saan nakabatay ang PyTorch.
- IKAW – Ang “ operating system 'Ang library ay ginagamit upang pangasiwaan ang mga gawaing nauugnay sa mga variable ng kapaligiran tulad ng ' pytorch_cuda_alloc_conf ” pati na rin ang direktoryo ng system at ang mga pahintulot ng file:
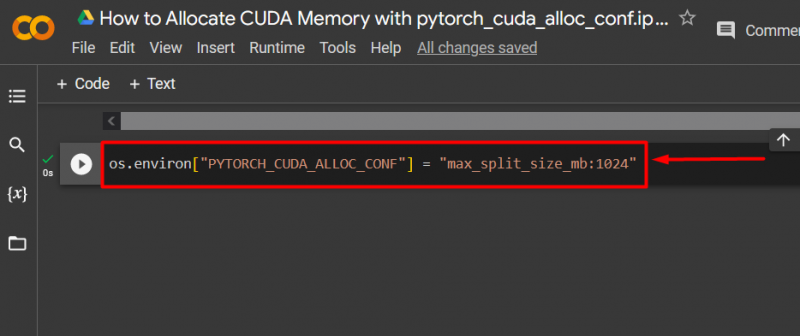
Hakbang 3: Ilaan ang CUDA Memory
Gamitin ang ' pytorch_cuda_alloc_conf 'paraan upang tukuyin ang maximum na laki ng hati gamit ang ' max_split_size_mb ”:
Hakbang 4: Magpatuloy sa iyong PyTorch Project
Matapos matukoy ang ' IBA 'paglalaan ng espasyo na may ' max_split_size_mb ” opsyon, ipagpatuloy ang pagtatrabaho sa proyekto ng PyTorch bilang normal nang walang takot sa “ wala sa memorya ” pagkakamali.
Tandaan : Maa-access mo ang aming Google Colab notebook dito link .
Pro-Tip
Gaya ng nabanggit kanina, ang ' pytorch_cuda_alloc_conf ” paraan ay maaaring tumagal ng alinman sa mga opsyon sa itaas. Gamitin ang mga ito ayon sa mga partikular na kinakailangan ng iyong mga proyekto sa malalim na pag-aaral.
Tagumpay! Ipinakita lang namin kung paano gamitin ang ' pytorch_cuda_alloc_conf 'paraan upang tukuyin ang isang ' max_split_size_mb ” para sa isang proyekto ng PyTorch.
Konklusyon
Gamitin ang ' pytorch_cuda_alloc_conf ” paraan upang maglaan ng memorya ng CUDA sa pamamagitan ng paggamit ng alinman sa mga magagamit nitong opsyon ayon sa mga kinakailangan ng modelo. Ang mga opsyon na ito ay ang bawat isa ay sinadya upang maibsan ang isang partikular na isyu sa pagproseso sa loob ng mga proyekto ng PyTorch para sa mas mahusay na mga runtime at mas maayos na mga operasyon. Sa artikulong ito, ipinakita namin ang syntax upang magamit ang ' max_split_size_mb ” na opsyon upang tukuyin ang maximum na laki ng split.