Ipapaliwanag ng gabay na ito kung paano gumawa ng mga crawler para kumuha ng data mula sa S3 bucket.
Paano Gumawa ng Crawler para Kumuha ng Data Mula sa S3 Bucket?
Upang lumikha ng crawler sa AWS, bisitahin ang ' AWS Glue ” serbisyo mula sa dashboard ng Amazon:
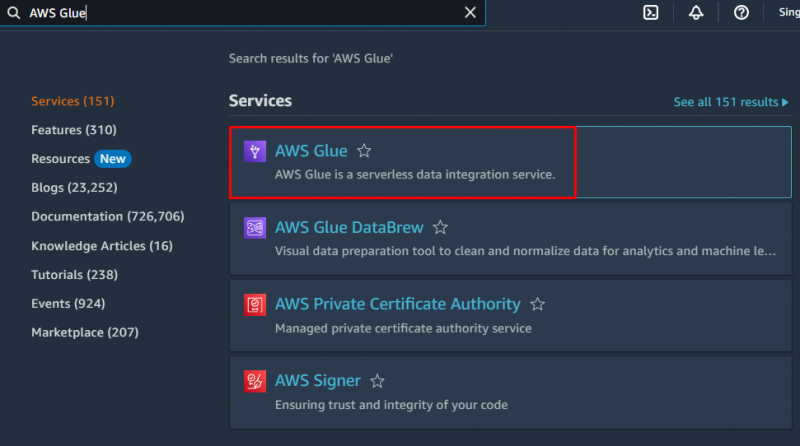
Mag-click sa “ Mga database ” button mula sa seksyong Catalog ng Data upang lumikha ng database:
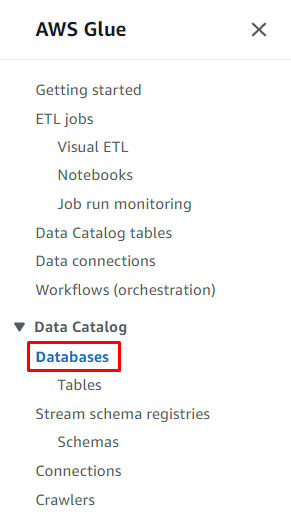
Mag-click sa “ Magdagdag ng database ” button upang simulan ang pagsasaayos:
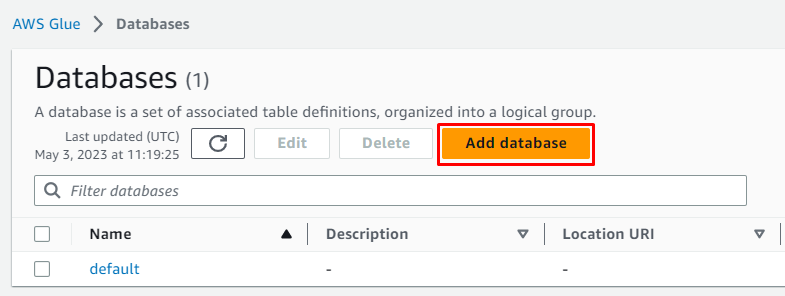
Ipasok ang pangalan ng database at iwanan ang lahat bilang ito ay opsyonal bago mag-click sa ' Lumikha ng database 'button:
Matagumpay na nalikha ang database:
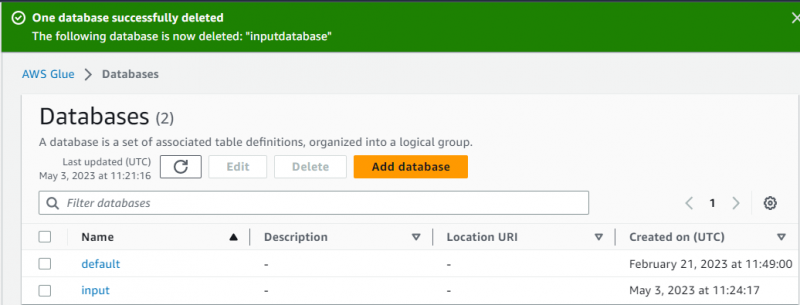
Pagkatapos nito, pumunta lang sa ' Mga crawler ” na pahina sa pamamagitan ng pag-click dito mula sa kaliwang panel:
Mag-click sa “ Lumikha ng crawler 'button:

I-type ang pangalan ng crawler at mag-click sa “ Susunod 'button:

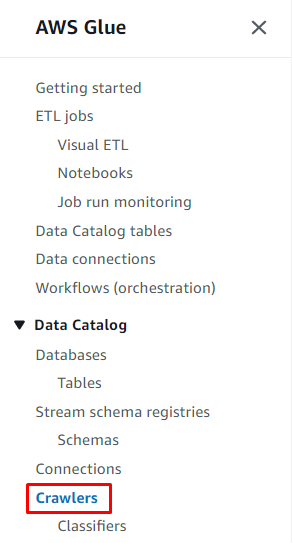
Mag-click sa “ Magdagdag ng data source ” button upang piliin ang pinagmulan ng data:
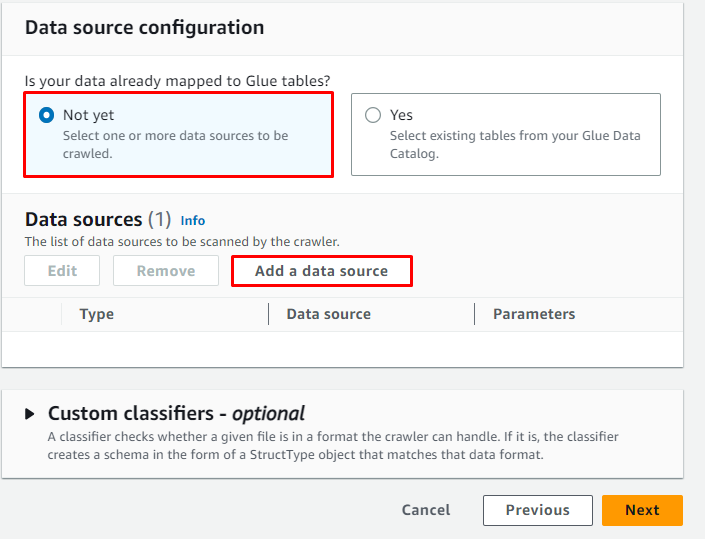
Upang suriin ang landas kung saan naka-imbak ang data, bisitahin ang serbisyo ng S3:
Tumungo sa S3 bucket kung saan ina-upload ang data. Ang gumagamit ay maaaring lumikha isang balde at mag-upload data dito mula sa AWS S3 dashboard:

Mag-click sa “ I-browse ang S3 ” button upang piliin ang landas ng data:
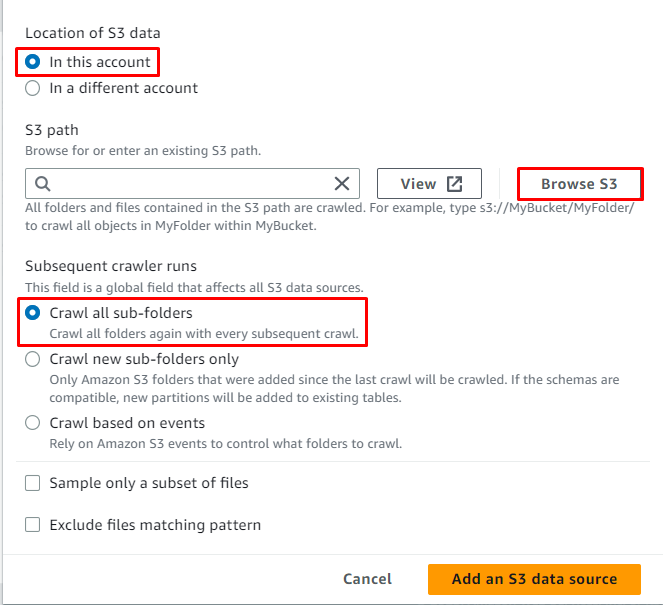
Piliin ang folder na naglalaman ng data, pagkatapos ay i-click ang “ Pumili 'button:

Ang S3 path ay napili, ngayon ay mag-click sa ' Magdagdag ng S3 data source 'button:

Kapag naidagdag na ang data source, i-click lang ang “ Susunod 'button:
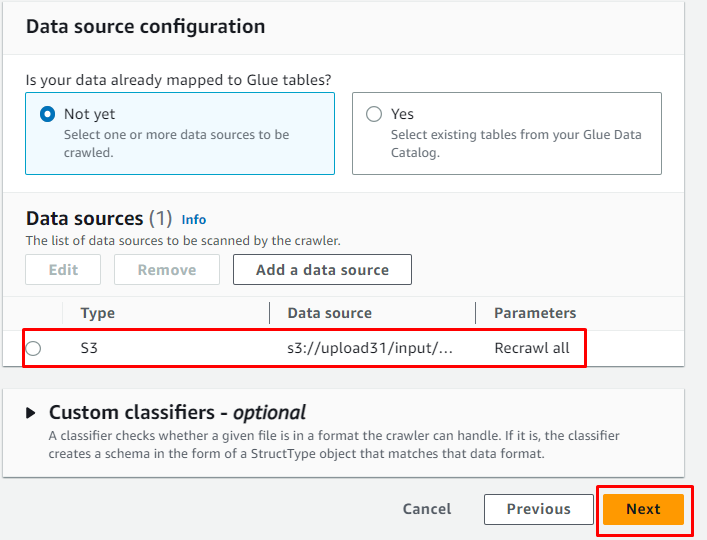
Idagdag ang tungkulin ng IAM at pagkatapos ay i-click ang “ Susunod 'button:
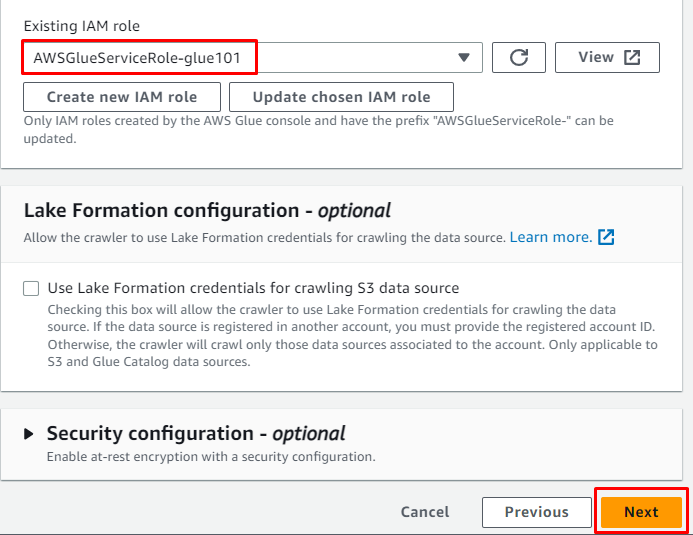
Ipasok ang target na database na ginawa nang mas maaga at pagkatapos ay i-type ang pangalan para sa talahanayan:
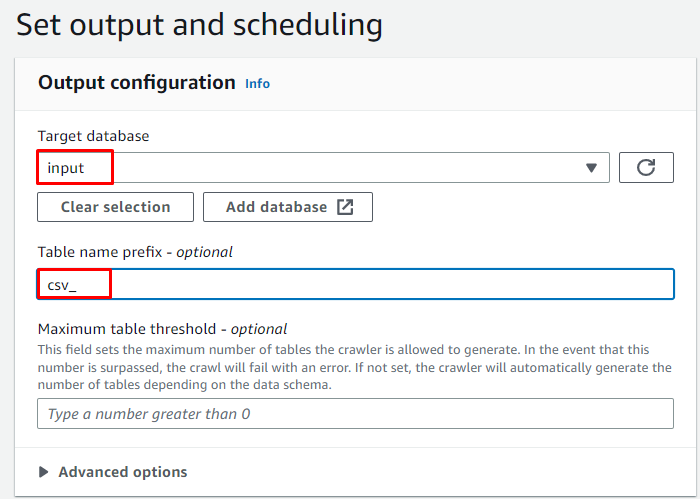
Piliin ang On demand na iskedyul para sa crawler at mag-click sa “ Susunod 'button:
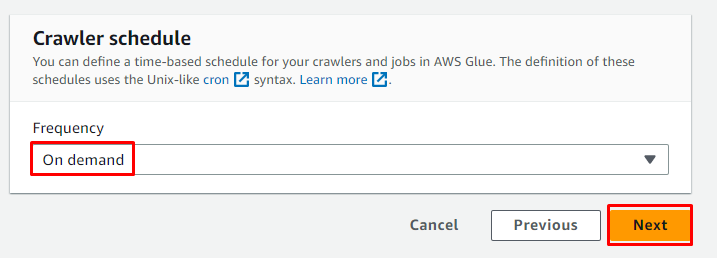
Suriin ang crawler at mag-click sa “ Lumikha ng crawler 'button:
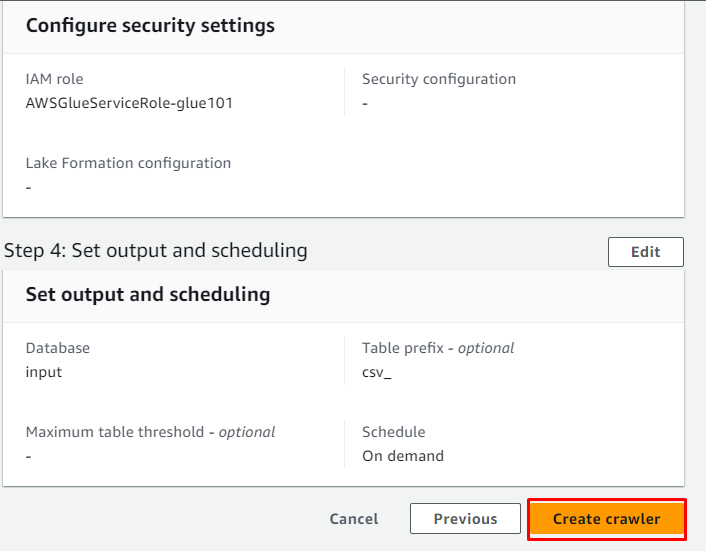
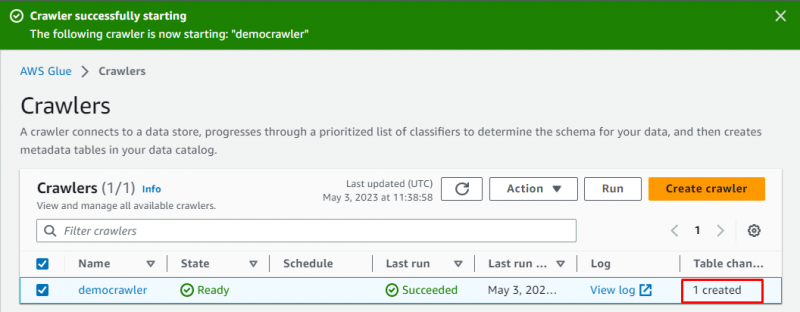
Matagumpay na nalikha ang crawler, i-click ang “ Takbo ” button pagkatapos piliin ito:

Aabutin ng ilang sandali upang patakbuhin ang crawler at kukuha ito ng data at gagawa ng talahanayan upang mag-imbak ng data:
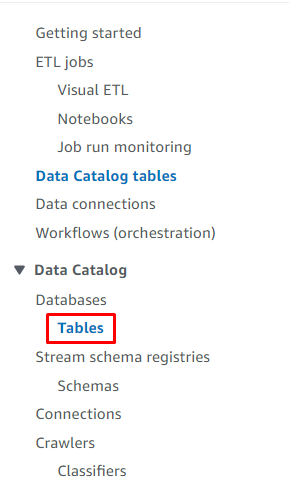
Tumungo sa ' Mga mesa ” na pahina mula sa dashboard ng Glue:
Piliin ang talahanayan sa pamamagitan ng pag-click sa pangalan nito:
Ang mga detalye ng kuwento ay ipinakita na naglalaman ng metadata ng kinuhang data:
Mag-scroll pababa sa pahina at piliin ang seksyon upang tingnan ang talahanayan na naglalaman ng data:
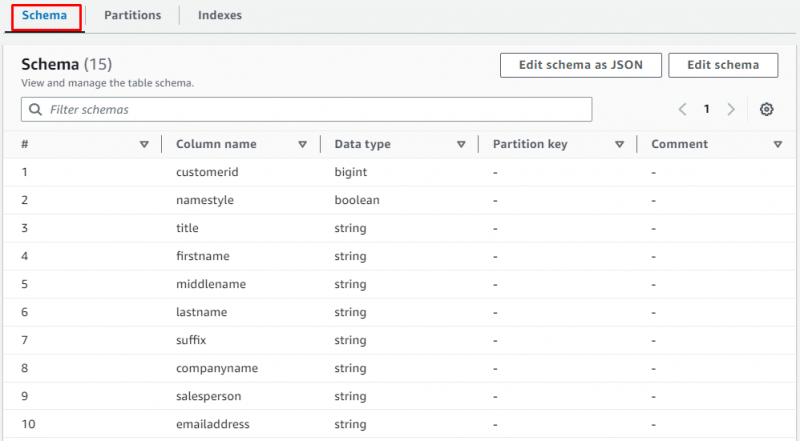
Iyon lang ang tungkol sa paggawa ng crawler para kumuha ng data mula sa S3 bucket.
Konklusyon
Para gumawa ng crawler para kumuha ng data mula sa S3 bucket, gumawa ng database sa AWS Glue kung saan iimbak ang na-crawl na data. I-configure ang crawler mula sa Glue dashboard sa pamamagitan ng pagbibigay ng source ng data (S3 bucket) at target na database. Patakbuhin ang crawler at kunin ang data mula sa S3 bucket patungo sa talahanayan ng database dahil masusing ipinaliwanag ng gabay na ito.