Ang Amazon Redshift ay isang cloud solution na inaalok ng AWS na tumutupad sa layunin ng isang data warehouse. Ang data warehouse ay isang malaking espasyo sa cloud na nag-iimbak ng napakaraming data. Ang pagkakaiba sa pagitan ng isang data warehouse at isang database ay ang dating ay hindi lamang nag-iimbak ng kasalukuyang data kundi pati na rin ang kumpletong kasaysayan ng data.
Matututunan ng artikulong ito ang tungkol sa Amazon Redshift ng AWS at ang mga uri ng data na sinusuportahan ng serbisyong ito.
Ano ang Amazon RedShift?
Ito ay isang cloud solution sa data warehousing na nakabatay sa 'PostgreSQL' . Gumagamit ito ng teknolohiya na tinatawag na 'Massively Parallel Processing (MPP)' upang iproseso ang mga petabytes ng data sa bilis ng kidlat. Nagbibigay ito ng madaling solusyon para sa real-time na hula batay sa makasaysayang data at mga solusyon sa streaming.
Ipinapakita ng sumusunod na figure ang gumaganang mekanismo ng Amazon Redshift:
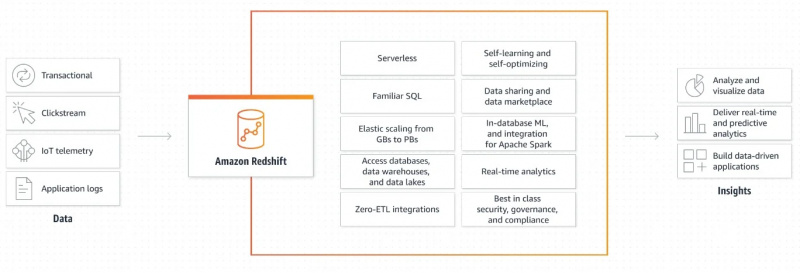
Ang graphical na paliwanag na ito kung paano gumagana ang Amazon Redshift ay napakasimple at malinaw. Nagbibigay ito sa amin ng impormasyon tungkol sa kung paano kinukuha at higit pang pinoproseso ang data upang makabuo ng mga output at lumikha ng mga application na batay sa data.
Ang arkitektura ng data warehouse ng Amazon Redshift ay makikita rin sa figure na ibinigay sa ibaba:
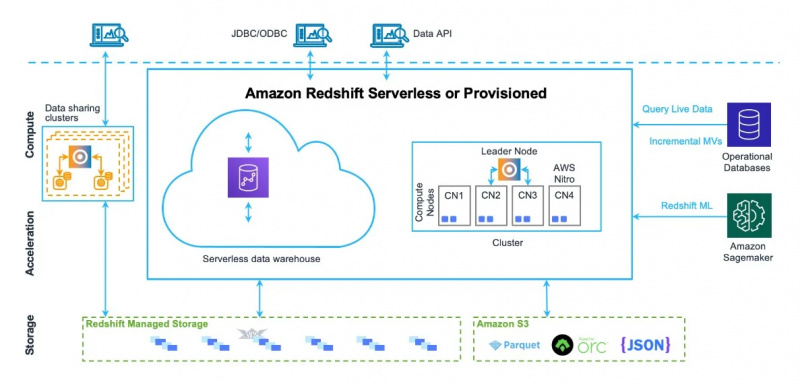
Ngayon, tutungo tayo sa mga gamit at feature ng serbisyong ito.
Mga tampok
Gaya ng nabanggit na, ang Amazon Redshift ay nakabatay sa PostgreSQL at gumagamit ng teknolohiyang tinatawag na Massively Parallel Processing na nagbibigay-daan dito na magproseso ng mga petabyte ng data sa hindi oras. Samakatuwid, nag-aalok ang Redshift ng maraming feature at gamit. Ang ilan sa mga tampok na ito ay nasa ibaba:
- Seguridad at Pag-encrypt ng Data.
- Business Analytics.
- Suporta sa Application na batay sa data.
- Mahuhulaang Pagsusuri.
- Awtomatikong Pag-uulit ng Gawain.
- Kasabay na Pag-scale ng Data.
- Data Warehousing.
Ang ilang mga karagdagang tampok ng serbisyong ito ay makikita sa figure na ibinigay sa ibaba:
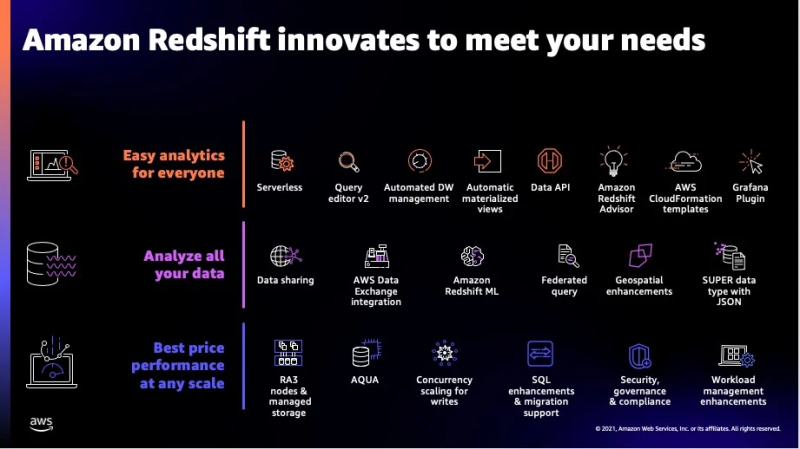
Ito ang karamihan sa mga feature na inaalok ng Redshift at ngayon ay lilipat kami sa mga uri ng data na sinusuportahan ng serbisyong ito.
Uri ng data
Ang Amazon Redshift ay isang solusyon sa warehousing ng data na may napakaraming feature. Sinusuportahan nito ang parehong structured at unstructured na mga uri ng data. Dahil ito ay batay sa PostgreSQL, ang data ay maaaring manipulahin sa pamamagitan ng simpleng mga query sa SQL.
Ngayon, lumitaw ang isa pang tanong, ibig sabihin, paano naiiba ang mga format ng data na ito sa isa't isa? Talakayin natin ang dalawang format ng data na ito.
Nakabalangkas na Data
Ang isang napaka-format na uri ng data na madaling isinalin ng mga algorithm ng machine learning ay tinatawag na structured data. Gumagana ang isang database ng SQL sa nakabalangkas na data. Ang structured data ay nasa tabular form gaya ng data na ginagamit ng relational database
Isa sa mga malawakang ginagamit na SQL database management system ay MYSQL. Ang arkitektura nito ay makikita sa ibaba sa ibinigay na figure:
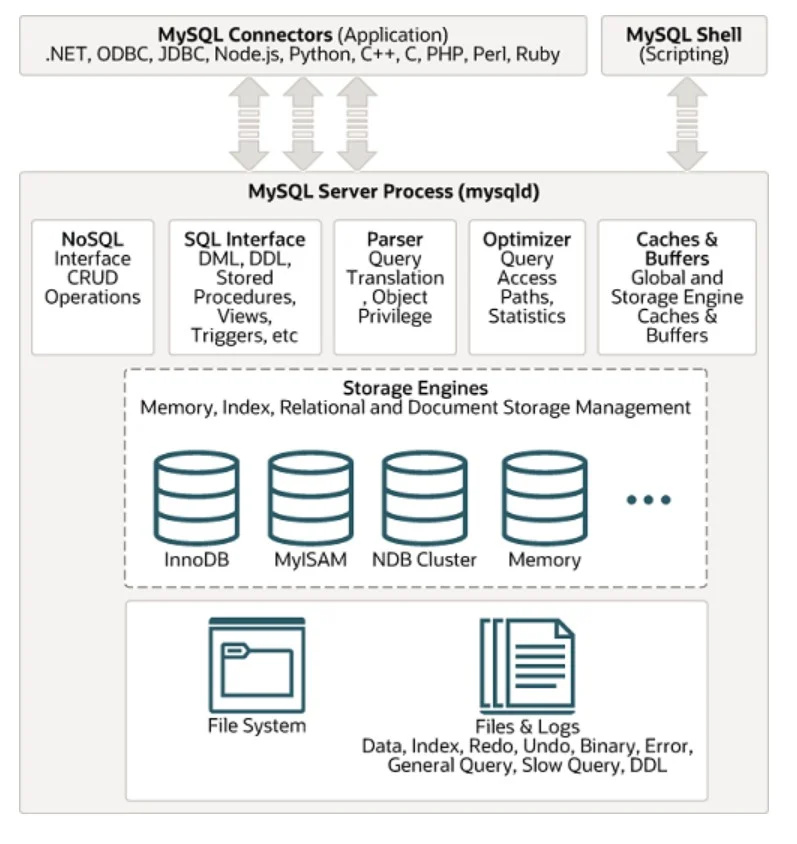
Hindi Nakabalangkas na Data
Ang hindi nakabalangkas na data ay mas kaunting pattern at mas kaunting format ang data gaya ng data na ginagamit sa mga database na hindi nauugnay. Ang MongoDB ay isang sikat na non-relational database. Ang mga query sa SQL ay hindi gumagana sa mga database na hindi nauugnay, kaya ang mga database na ito ay tinatawag ding mga database ng NoSQL.
Tulad ng nabanggit na, ang MongoDB ay isang non-structured database management system at ang arkitektura nito ay makikita sa ibaba sa ibinigay na figure:
Napagdaanan na namin ang dalawang pangunahing uri ng data na ginagamit sa mga database at pupunta na kami ngayon sa aktwal na mga uri ng data na sinusuportahan ng Amazon Redshift. Ang mga uri ng data na ito ay:
- Numeric Data
- Data ng Character
- Data ng Petsa
- Data ng Boolean
- HLLSKETCH Data
- SUPER Data
- KAPALIT na Data
Talakayin natin ang mga uri ng data na ito:
Numeric Data
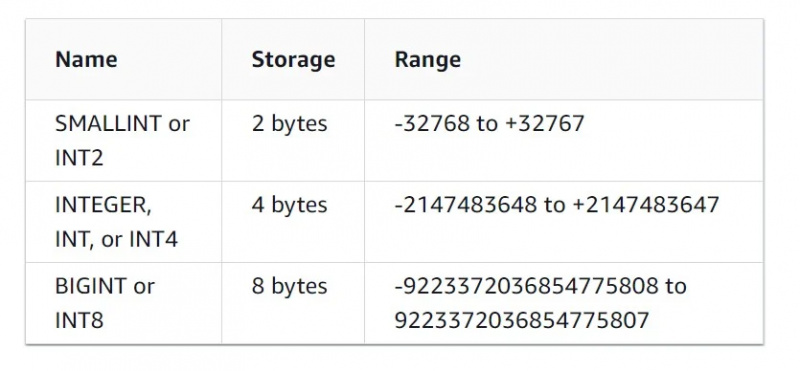
Ang uri ng data na ito ay maliwanag. Sinusuportahan nito ang data na nasa anyo ng mga integer, decimal, floating point, at iba pang mga numeric na uri ng data.
Ang mga katangian ng integer data type ay makikita sa figure sa ibaba:
Ang uri ng desimal na data ay nag-iimbak ng data batay sa katumpakan mula sa user. Ang mga katangian nito ay ang mga sumusunod:

Data ng Character
Ang mga uri ng data ng CHAR at VARCHAR ay nasa ilalim ng kategorya ng mga uri ng data na nakabatay sa character. Ang NCHAR at NVARCHAR ay mga uri din ng data ng character type. Hindi tulad ng CHAR at VARCHAR, ang dalawang uri ng data na ito ay nag-iimbak ng nakapirming haba, mga Unicode na character. Tingnan natin ang mga katangian ng mga uri ng data na ito, gaya ng:
- Ang CHAR, CHARACTER, NCHAR ay may saklaw na 4KB.
- VARCHAR, NVARCHAR ay may saklaw na 64KB.
- Ang BPCHAR ay may hanay na 256 Bytes.
- Ang TEXT ay may saklaw na 260 Bytes.
Data ng Petsa
Ang mga uri ng data ng datetime ay DATE, TIME, TIMETZ, TIMESTAMP, TIMESTAMPTZ. Ang mga functional na kakayahan ng mga uri ng data na ito ay ang mga sumusunod:
- Ang DATE ay nag-iimbak lamang ng mga petsa sa kalendaryo.
- Ang TIME ay nag-iimbak ng oras nang walang reference sa anumang time zone. Ito ay UTC, bilang default.
- Ang TIMETZ ay nag-iimbak ng oras bilang pagtukoy sa time zone. Ito ay UTC sa parehong mga talahanayan ng gumagamit at mga talahanayan ng system, bilang default.
- Ang TIMESTAMP ay hindi lamang kasama ang oras kundi pati na rin ang mga petsa. Ito ay UTC sa parehong mga talahanayan ng gumagamit at mga talahanayan ng system, bilang default.
- Ang TIMESTAMPTZ ay hindi lamang kasama ang oras kundi pati na rin ang mga petsa. Ito ay UTC sa mga talahanayan ng user lamang, bilang default.
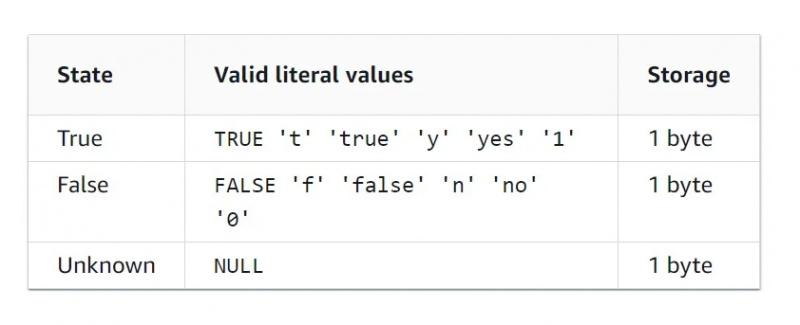
Data ng Boolean
Ang uri ng data ng Boolean ay isang binary na uri ng data, na nangangahulugang mayroon lamang dalawang halaga. Ang talahanayan ng mga katangian para sa uri ng data ng Boolean ay ibinigay sa ibaba sa figure:
HLLSKETCH Data
Ang uri ng data na ito ay ginagamit upang mag-imbak ng mga sketch. Ang redshift ay maaaring kumatawan sa mga sketch sa alinman sa kalat-kalat o siksik na anyo. Nagsisimula ang mga sketch bilang kalat-kalat at unti-unting nagiging siksik kapag ang isang siksik na format ay nagbibigay ng higit na kahusayan sa pamamagitan ng pagsunod sa link.
SUPER Data
Ang uri ng data na ito ay tumatalakay sa hindi nakaayos na data na maaaring nasa anyo ng mga array, nested structure, o JSON. Walang modelo o format ng data. Maaaring tuklasin ng mga user ang higit pang impormasyon sa pamamagitan ng pag-navigate sa link.
KAPALIT na Data
Ang uri ng data na ito ay nag-iimbak din ng mga character. Gayunpaman, ang haba ay limitado. Pinapayagan ng Amazon Redshift ang pag-cast ng data ng VARBYTE sa anumang uri ng integer o data ng uri ng character. Upang makakuha ng higit pang impormasyon tungkol sa datatype na ito, sundan ang link sa ibaba.
Ito lang ang mayroon sa Amazon Redshift at ang mga uri ng data na sinusuportahan nito.
Konklusyon
Ang Amazon Redshift ay isang serbisyo ng AWS na sa pangunahing anyo nito ay nagsisilbi sa layunin ng isang data warehouse ngunit ito ay isang napakalakas at tampok na solusyon para sa analytics at hula. Tinalakay ng artikulong ito ang Redshift at ang mga uri ng data na sinusuportahan nito. Ang mga uri ng data na ito ay ipinaliwanag nang maikli kasama ang kanilang mga katangian.